
Image: Getty
Thomas Rid ( @RIDT ) is Professor of Strategic Studies at Johns Hopkins University/SAIS. Rid was a witness in one of the first open hearings on Russian disinformation of the Senate Select Committee on Intelligence in March, where he called out Twitter as an " unwitting agent " of adversarial intelligence services.Twitter is the most open social media platform, which is partly why it's used by so many politicians, celebrities, journalists, tech types, conference goers, and experts working on fast-moving topics. As we learned over the past year, Twitter's openness was exploited by adversarial governments trying to influence elections. Twitter is marketing itself as a news platform, the go-to place to find out, in the words of its slogan, "What's happening?"So what's happening with disinformation on Twitter? That is very hard to tell, because Twitter is actively making it easier to hide evidence of wrongdoing and making it harder to investigate abuse by limiting and monitoring third party research, and by forcing data companies to delete evidence as requested by users. The San Francisco-based firm has long been the platform of choice for adversarial intelligence agencies, malicious automated accounts (so-called bots), and extremists at the fringes. Driven by ideology and the market, the most open and liberal social media platform has become a threat to open and liberal democracy.In the course of late 2016 and 2017, Facebook tried to confront abuse: by hiring a top-notch security team; by improving account authentication; and by tackling disinformation. Twitter has done the opposite—its security team is rudimentary and reclusive; the company seems to be in denial on the scope of disinformation; and it even optimised its platform for hiding bots and helping adversarial operators to delete incriminating evidence—to delete incriminating evidence not just from Twitter, but even from the archives of third party data providers. I spoke with half a dozen analysts from such intelligence companies with privileged access to Twitter data, all of whom asked for anonymity for fear of upsetting their existing relationship with Twitter. One analyst joked that he would to cut off my feet if I mentioned him or his firm. Twitter declined to comment on the record for this story two times.Twitter is libertarian to the core. The platform has always allowed users to register any available handle, on as many accounts as they want, anonymously, no real name required, in sharp contrast to Facebook. Users could always delete content, undo engagements, and suspend their accounts. There are strong privacy arguments in favor of giving users full control of their data, even after publication. From the beginning, Twitter has reflected those values and held on to them against pressure from undemocratic governments. But its openness, particularly the openness for deletion, anonymity, and automation, has made the platform easy to exploit.Let's start with the bots. Twitter is teeming with automated accounts. "The total number of bots on Twitter runs into the millions, given that an individual bot action can involve over 100,000 accounts," Ben Nimmo, a bot hunter at the Atlantic Council, told me. A precise estimate is hard to come by. In March 2017, one study by researchers at the University of Indiana and the University of Southern California estimated that up to 15 percent of all Twitter accounts are bots. In September, another study from Rice University put the number at up to 23 percent, out of a global active user base of approximately 330 million.Individual cases provide a better measure. At one point in the summer of 2016, around 17,000 bot accounts were put to work amplifying the Russian election interference, estimated one company with direct access to Twitter data. That number only takes into account highly repetitive posts that explicitly referred to Guccifer 2 and DC Leaks, two Russian front organizations called out by the US intelligence community, so the actual number of amplification bots was likely much higher.A year later, the bot problem had not been contained. On August 29, 2017, Nimmo tried to trigger an "attack" by Russia-linked bots by mentioning the right keywords in on one of his posts in order to bring the problem to the attention of Twitter: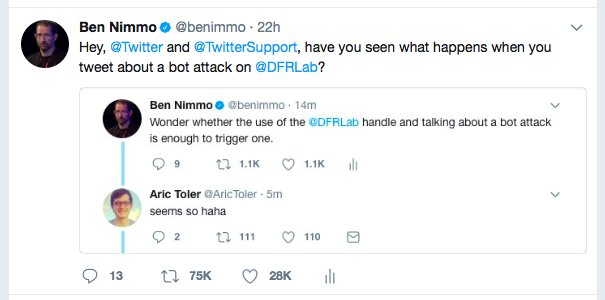 It worked: he got retweeted (and thus spammed) by more than 75,000 bots within hours. Twitter likely suspended more than 50,000 accounts, but as of last week, the posts still had around 18,000 automated spam engagements.Twitter makes automating accounts easy. A moderately technical user can create and run a simple bot within hours. Camouflaging a primitive online robot as a blue collar worker from Wisconsin is trivial. Professionals can easily mass-produce bots, link them up, and commandeer them as a whole. Botnets, therefore, are pervasive. For example: one editorial in The New York Times, "Trump Is His Own Worst Enemy," was amplified and "attacked" by four different botnets in sequence, through RTs, likes, and @replies. Many of the accounts involved in these waves of amplification averaged well more than 1,500 tweets per day, an inhuman rate of activity.Spotting bots can be hard for laypersons. An experienced user may be able to recognize an individual account as fake without much effort. But recognizing fake engagement is much harder: if a post has, say, 4,368 retweets and 2,345 likes, even advanced and cautious users will intuitively ascribe more importance to the message—without ever manually checking if the retweets are real. Bots don't sleep, they don't get tired, and they don't ever lose focus. The volume of fake traffic is therefore higher than the volume of fake accounts.Nimmo told me an estimate of forged engagement is very difficult, and then cautiously added that fake activity could be as much as half the total traffic on Twitter. How many of the tens of thousands of nearly instant likes and retweets that each single post from Donald Trump received during the 2016 campaign, for example, were generated by genuine human Trump supporters? Probably a significant number: he won, after all. But we simply cannot tell how significant the automated Russian amplification of @realdonaldtrump has been; probably not even Twitter knows the precise answer.Recognizing automated abuse is easy for analysts in principle. One data analytics expert with privileged access to Twitter data was particularly agitated when I asked him what he would ask Twitter in the upcoming Senate hearing on Tuesday: "Do they realize how easy it is to find this stuff?" He added: "It's beyond trivial." Patterns of behaviour are often a giveaway. But spot-the-bot should be even easier for Twitter, as it can see what's happening under the hood. Yet Twitter's internal analysis of Russia-linked automated activity during the 2016 election found only 36,746 accounts—a number that is understating the abuse by an order of magnitude.For Twitter's methodology and internal telemetry is misleading: seeing what phone carrier or email address was used, what language settings an account has, or if a user logs in from a Russian IP address is not enough, as even a moderately cautious adversary can easily camouflage such indicators. Only state-of-the-art network analysis that takes into account subtle patterns of automated behaviour to link bots and abusers to each other (as opposed to static country indicators) will shed light on the full extent of manipulation. Twitter's lowball number, as provided in their Senate testimony on 31 October 2017, also ignored camouflaged, deleted, and suspended bot activity.Meanwhile Twitter is granting the same level of privacy protection to hives of anonymous bots commandeered by authoritarian spy agencies as it grants to an American teenager tweeting under her real name from her sofa at home.As Twitter grew in popularity, its data became more attractive and more valuable. A small number of companies got into the business of analysing and re-selling access to the full take of Twitter data, the so-called "firehose." But Twitter grew alarmed as it lost more control of is user-generated data. By April 2015, the company announced it would take steps "toward developing more direct relationships with data customers." Twitter wanted more control over what third parties do with its data.One of the hardest questions had been left unresolved over the years of growth: should a post—or an account—be deleted not just from Twitter when the user deletes the content, but also from the databases and from the archives of third party providers? This practice is known as "cross-deletion" in the data analytics community.Already in 2014, Twitter's policy for developers had a section named Respect Users' Control and Privacy. Developers, the policy stated back then, should "take all reasonable efforts" in order to "delete content that Twitter reports as deleted or expired." In developer jargon this policy is known as cross-deletion: removal of content across different platforms, public and private (other social media platforms like Instagram and Tumblr have similar policies).The result: data and intelligence companies with access to the full Twitter firehose operated in a gray space on cross-deletion. Some of them kept the deleted data for analysis even after users deleted posts or accounts, or after users un-engaged with content. After all deletions are likely to be of particular interest for follow-on analysis. If a user tries to hide something, or clean something up, that something is by definition more interesting.By mid-2016, Twitter was slowly clawing back full control of the firehose. Data companies now had to submit "use cases" to work with firehose data. Twitter soon was in a position to monitor search queries and analysis by third party providers. By the summer of 2016, some data companies I spoke with adjusted their policies to implement cross-deletion more thoroughly and more quickly for fear of losing access to the Twitter data stream.A year later, by June 20, 2017—as the full extent of social media-amplified meddling in the 2016 election was in full public view—Twitter made the problem worse. In an update to its policy document (section C-3), Twitter made it even harder for analytics companies to keep deleted or modified content in their archives. No more grey areas to keep data. And Twitter was now surveilling independent analysis done with its firehose data. Every data firm with privileged access I spoke with was in a state of near panic that they could lose access in punishment for doing "forbidden research," as one concerned analyst said.The result of the API policy change: Russian operators can clean up their traces from the public domain as well as from the archives, thus hiding evidence from ongoing investigations even more easily. Shadowbrokers, likely one of the most aggressive components of the wider disinformation operation, started deleting its posts in late June.Twitter's poor market performance makes the problem worse. The social news platform, in contrast to Facebook or Google, has never made money. It therefore pays more attention to its shareholders. One of the most important metrics for its stock price is the "active user base." Millions of bots and fake accounts are boosting the numbers, making the active user base appear much larger than it actually is. The open market is thus creating an incentive to hide the bots. Were Twitter forced to admit the true extent of fake accounts and fake traffic on its platform, it could be the death of the little blue bird.
It worked: he got retweeted (and thus spammed) by more than 75,000 bots within hours. Twitter likely suspended more than 50,000 accounts, but as of last week, the posts still had around 18,000 automated spam engagements.Twitter makes automating accounts easy. A moderately technical user can create and run a simple bot within hours. Camouflaging a primitive online robot as a blue collar worker from Wisconsin is trivial. Professionals can easily mass-produce bots, link them up, and commandeer them as a whole. Botnets, therefore, are pervasive. For example: one editorial in The New York Times, "Trump Is His Own Worst Enemy," was amplified and "attacked" by four different botnets in sequence, through RTs, likes, and @replies. Many of the accounts involved in these waves of amplification averaged well more than 1,500 tweets per day, an inhuman rate of activity.Spotting bots can be hard for laypersons. An experienced user may be able to recognize an individual account as fake without much effort. But recognizing fake engagement is much harder: if a post has, say, 4,368 retweets and 2,345 likes, even advanced and cautious users will intuitively ascribe more importance to the message—without ever manually checking if the retweets are real. Bots don't sleep, they don't get tired, and they don't ever lose focus. The volume of fake traffic is therefore higher than the volume of fake accounts.Nimmo told me an estimate of forged engagement is very difficult, and then cautiously added that fake activity could be as much as half the total traffic on Twitter. How many of the tens of thousands of nearly instant likes and retweets that each single post from Donald Trump received during the 2016 campaign, for example, were generated by genuine human Trump supporters? Probably a significant number: he won, after all. But we simply cannot tell how significant the automated Russian amplification of @realdonaldtrump has been; probably not even Twitter knows the precise answer.Recognizing automated abuse is easy for analysts in principle. One data analytics expert with privileged access to Twitter data was particularly agitated when I asked him what he would ask Twitter in the upcoming Senate hearing on Tuesday: "Do they realize how easy it is to find this stuff?" He added: "It's beyond trivial." Patterns of behaviour are often a giveaway. But spot-the-bot should be even easier for Twitter, as it can see what's happening under the hood. Yet Twitter's internal analysis of Russia-linked automated activity during the 2016 election found only 36,746 accounts—a number that is understating the abuse by an order of magnitude.For Twitter's methodology and internal telemetry is misleading: seeing what phone carrier or email address was used, what language settings an account has, or if a user logs in from a Russian IP address is not enough, as even a moderately cautious adversary can easily camouflage such indicators. Only state-of-the-art network analysis that takes into account subtle patterns of automated behaviour to link bots and abusers to each other (as opposed to static country indicators) will shed light on the full extent of manipulation. Twitter's lowball number, as provided in their Senate testimony on 31 October 2017, also ignored camouflaged, deleted, and suspended bot activity.Meanwhile Twitter is granting the same level of privacy protection to hives of anonymous bots commandeered by authoritarian spy agencies as it grants to an American teenager tweeting under her real name from her sofa at home.As Twitter grew in popularity, its data became more attractive and more valuable. A small number of companies got into the business of analysing and re-selling access to the full take of Twitter data, the so-called "firehose." But Twitter grew alarmed as it lost more control of is user-generated data. By April 2015, the company announced it would take steps "toward developing more direct relationships with data customers." Twitter wanted more control over what third parties do with its data.One of the hardest questions had been left unresolved over the years of growth: should a post—or an account—be deleted not just from Twitter when the user deletes the content, but also from the databases and from the archives of third party providers? This practice is known as "cross-deletion" in the data analytics community.Already in 2014, Twitter's policy for developers had a section named Respect Users' Control and Privacy. Developers, the policy stated back then, should "take all reasonable efforts" in order to "delete content that Twitter reports as deleted or expired." In developer jargon this policy is known as cross-deletion: removal of content across different platforms, public and private (other social media platforms like Instagram and Tumblr have similar policies).The result: data and intelligence companies with access to the full Twitter firehose operated in a gray space on cross-deletion. Some of them kept the deleted data for analysis even after users deleted posts or accounts, or after users un-engaged with content. After all deletions are likely to be of particular interest for follow-on analysis. If a user tries to hide something, or clean something up, that something is by definition more interesting.By mid-2016, Twitter was slowly clawing back full control of the firehose. Data companies now had to submit "use cases" to work with firehose data. Twitter soon was in a position to monitor search queries and analysis by third party providers. By the summer of 2016, some data companies I spoke with adjusted their policies to implement cross-deletion more thoroughly and more quickly for fear of losing access to the Twitter data stream.A year later, by June 20, 2017—as the full extent of social media-amplified meddling in the 2016 election was in full public view—Twitter made the problem worse. In an update to its policy document (section C-3), Twitter made it even harder for analytics companies to keep deleted or modified content in their archives. No more grey areas to keep data. And Twitter was now surveilling independent analysis done with its firehose data. Every data firm with privileged access I spoke with was in a state of near panic that they could lose access in punishment for doing "forbidden research," as one concerned analyst said.The result of the API policy change: Russian operators can clean up their traces from the public domain as well as from the archives, thus hiding evidence from ongoing investigations even more easily. Shadowbrokers, likely one of the most aggressive components of the wider disinformation operation, started deleting its posts in late June.Twitter's poor market performance makes the problem worse. The social news platform, in contrast to Facebook or Google, has never made money. It therefore pays more attention to its shareholders. One of the most important metrics for its stock price is the "active user base." Millions of bots and fake accounts are boosting the numbers, making the active user base appear much larger than it actually is. The open market is thus creating an incentive to hide the bots. Were Twitter forced to admit the true extent of fake accounts and fake traffic on its platform, it could be the death of the little blue bird.
All of this makes Twitter a convenient disinformation platform. Jack Dorsey, the CEO, has built a news platform optimised for disinformation—not by intention, but in effect.So what should be happening? Twitter should own up to its values, acknowledge it's a public news platform (in contrast to other social media networks), and stop editing the news. After all, Twitter designed its service in a way that gives every single regular post a publicly accessible and unique URL, no login required to view. Such openness has been a key ingredient in the company's recipe for success. Tweets are on the public record, indeed some have become the public record.The Economist, in theory, could decide to give its readers the option to unpublish letters-to-the editor, as published in the news magazine. But it is unimaginable that The Economist would even dare to ask the Library of Congress to unpublish content from its archives. Yet this is what Twitter is enforcing—both figuratively and literally, as Twitter's Library of Congress archiving project, announced in 2010, has stalled.The US President shouldn't be able to edit history. Russian spies and bots shouldn't be able to falsify the historical record. Nor should a Silicon Valley firm with a highly uncertain future be able to mess with how we remember our past.
Advertisement
Advertisement
Advertisement
Advertisement
Advertisement
Advertisement
All of this makes Twitter a convenient disinformation platform. Jack Dorsey, the CEO, has built a news platform optimised for disinformation—not by intention, but in effect.So what should be happening? Twitter should own up to its values, acknowledge it's a public news platform (in contrast to other social media networks), and stop editing the news. After all, Twitter designed its service in a way that gives every single regular post a publicly accessible and unique URL, no login required to view. Such openness has been a key ingredient in the company's recipe for success. Tweets are on the public record, indeed some have become the public record.The Economist, in theory, could decide to give its readers the option to unpublish letters-to-the editor, as published in the news magazine. But it is unimaginable that The Economist would even dare to ask the Library of Congress to unpublish content from its archives. Yet this is what Twitter is enforcing—both figuratively and literally, as Twitter's Library of Congress archiving project, announced in 2010, has stalled.The US President shouldn't be able to edit history. Russian spies and bots shouldn't be able to falsify the historical record. Nor should a Silicon Valley firm with a highly uncertain future be able to mess with how we remember our past.